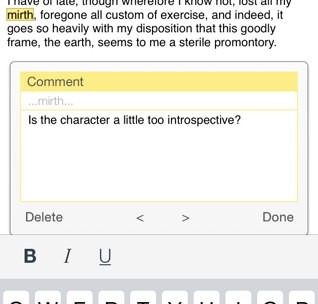
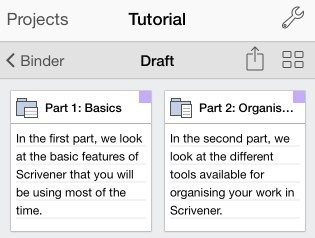
So, that’s between three and four months on a single (but integral) feature. (And while I’ve been doing this, Tammy, our iOS developer, has been adding various “smaller” features that had to wait until late in development – printing, basic compiling, import and export, statistics, split and merge, find and replace… The sort of features that it’s easy for users to forget when suggesting that Scrivener for iOS should just be simple and only have the basics, but without which, Scrivener for iOS would feel crippled. And even some of these smaller features can take a couple of weeks each to implement, of course.)
The trouble is that it’s not only non-programmers who (understandably) don’t appreciate how long seemingly simple things can take to code – we do it ourselves. We’ll often think that a feature will only take us a day or two to complete, then find ourselves growling at the screen, desperate to have done with it, two weeks later. (This is no doubt why software and games are so notorious for being delayed throughout the industry.)
In a program as complex as Scrivener (even on iOS it requires a degree of internal complexity if it is to work with the desktop version), where various features can take a month or more to implement, the time creeps up on you and suddenly two years have passed… There are certainly programs out there that can be written in three or four months, but sadly, Scrivener isn’t one of them.
Not that “development takes time” is the whole picture. Something like Scrivener can easily take a couple of years to develop properly, but it has now been two and a half years since we started work on it; we had hoped it would be finished by now as much as anyone else – we don’t enjoy frustrating those of our users who write on mobile devices. The other big factor for us has been scaling up. Scrivener started out as a hobby – the software I wanted for my own writing. I wanted it so much that I taught myself how to code in order to create it. For the first couple of years, L&L was a one-man operation, and we are still a very small team. I work alone on the Mac version, two programmers work as a discrete unit on the Windows version, we have a couple of other full-time team members who write and maintain the manual and tutorials and handle all QC testing and some support, and we have a couple of part-time support staff. We have no central offices but are scattered across the world (the UK, US, Australia and Bulgaria). None of which is unusual for shareware, “artisan” software such as Scrivener.
The wonders of the information age make it easy for geographically-scattered teams to stay in constant touch and work together, but as a small company with such a setup, it meant that it was not possible for us just to hire some programmers and stand over them until the iOS version was finished. I was always adamant that I would not write the iOS version myself, because I’ve seen too much Mac software suffer as its developer has spent all his or her time working on iOS, and that would have been unfair to our existing user base. (Moreover, the Mac version is where I live for my own writing, and Scrivener is always going to be predominantly a desktop program.) So it was key to find someone self-motivated, with a good understanding of Scrivener, who could develop Scrivener for iOS and keep on developing it into the future, beyond version 1.0.
As I announced last year, unfortunately our first developer had to step away from the project because of family health issues, which had also stalled development progress throughout the eighteen months she had been working on it. We were very fortunate to find Tammy Coron, an experienced iOS developer and Scrivener user, to take over development. When she took over, she made the painful decision to rewrite much of the existing code, in part because of new technologies that had been introduced with iOS 7.0 (a rich text system at last!). Which means that while our iOS version has been in various stages of development since the end of 2011, the form it is in now has only been in development for just over a year.
We are really looking forward to releasing the iOS version – in many ways it’s become the proverbial albatross around our necks.* But it is getting there, and we hope the subsection of Scrivener users who are eager for an iOS version will be patient for a little while longer. We are genuinely grateful for your enthusiasm. I’m not known for great reserves of patience myself, so I do understand the frustration of some users who are more vocal in their eagerness, but to those I would say, please do try to remember that we want to get our iOS version into your hands as much as you want it. We’re a tiny company but we have put a lot of energy and resources into the iOS version (and for all we know it could be a loss-making venture), and we think Scrivener users will be happy with the final product.
I’ll post later in the year more on what sort of features to expect, but suffice to say that it has full rich text editing, a corkboard, an outliner, an inspector and, on the iPad version, the ability to view research alongside your text as you type. It is, essentially, Scrivener on iOS.
P.S. For anyone interested, I’ve uploaded a sort of developer diary for the iOS version here:
A Scrivener for iOS Developer Diary
If nothing else, it should show at least that the iOS version has been in continual development, hitting snags along the way, even if progress has seemed glacial to the outside world.