

Scrivener 3 brings with it much better support for creating Epub and Kindle files.
Note: This blog post pertains to upcoming features in Scrivener 3, which will be released on macOS later this year and will follow on Windows during early 2021.
Additional note: This blog post specifically relates to the development of the macOS version, but the improvements that resulted from this development are coming to Windows too.
One of the many areas of Scrivener I wanted to improve for version 3 was its Epub export. Scrivener 2.x creates Epub 2 files, even though the latest Epub specification at the time of writing is 3.1. Moreover, internally those Epub 2 files are a little messier than is ideal. An Epub file is essentially just a zip package containing a bunch of HTML, CSS and XML files (CSS files define the formatting used in the HTML). Scrivener 2.x creates a separate CSS file for each HTML file in the book (when it’s better practice to create a single CSS file that is used by all of the HTML files) and the HTML is a little messy.
Ordinarily, the internals of an Epub file shouldn’t worry anyone except for those who are passionate about parsimony—the most important thing is that it looks as it should on e-reader devices. However, the use of multiple CSS files has a deleterious effect on Kindle files. When you export a Kindle .mobi file from Scrivener, it is constructed using the same code as Epub export, and then converted to Kindle format using Amazon’s KindleGen utility. Scrivener-generated Kindle files look great on Kindle devices, but they don’t work so well with Amazon’s “Look Inside” feature. This is because a bug in Amazon’s “Look Inside” feature means it takes formatting from only the first CSS file in the book, regardless of whether or not it’s the one that’s supposed to be used for the text being displayed. This can result in the text using the wrong formatting—not a great introduction to your book for the reader!
All of these issues originate from a single cause: the HTML generator that Scrivener 2.x uses. To create ebook files, I have to convert the rich text in Scrivener’s editor to HTML format. Apple provides an HTML converter built in to the text system, so I have always used that. However, Apple’s converter only supports HTML 4 (whereas Epub 3 requires HTML 5), it produces rather messy HTML with a lot of cruft, and I have very little control over it (there’s no way of setting it up to use a single CSS for multiple output files, for instance).
For Scrivener 3, then, I needed to find a way of converting Scrivener’s rich text to HTML 5, and I needed more control over the HTML generation. I began by hunting high and low (sing: there’s no end to the lengths I’ll go to) for a third-party converter, but there is very little out there in the way of third-party converters that work with Apple’s text engine. I considered writing my own converter from scratch, but that would be a mammoth undertaking that would require regular maintenance.
The solution? MultiMarkdown. MultiMarkdown can already convert text to HTML 5, and it does so cleanly and allows a great deal of control and flexibility.
The problem? For MultiMarkdown to convert text to HTML 5, the text has to be written in MultiMarkdown syntax—that is, with asterisks denoting bold and italics, pipes and dashes representing tables, greater-than symbols representing the start of block quote paragraphs, and so on. You can’t just pipe rich text though MultiMarkdown and have it come out with the formatting intact.
The solution to the problem with the solution? I spent a couple of weeks writing a full rich-text-to-MultiMarkdown converter. This takes a rich text document and converts it all to MultiMarkdown syntax: bold, italics, footnotes, tables, lists, block quotes—the works. With that in place, to generate an Epub 3 file or an improved Kindle file, internally I could convert the rich text to MultiMarkdown and then the MultiMarkdown to HTML 5.
The result of all of this work is this:
- Scrivener 3 can export to Epub 3 format.
- Its Kindle export is also much improved, and should now work fine with Amazon’s “Look Inside” feature.
- The internals of Epub 3 and Kindle files are tidier, containing only a single CSS file.
- In Compile, you can optionally override the CSS that is generated. This means that those with experience in CSS will be able to add features such as drop caps (although not many e-readers support that yet) or anything else that CSS and e-readers support.
- In Scrivener 3, as a nifty side effect of all this work, you can export to any MultiMarkdown format even if you don’t write using MultiMarkdown syntax: you can simply tick a checkbox and have all of the rich text converted to MultiMarkdown during export.
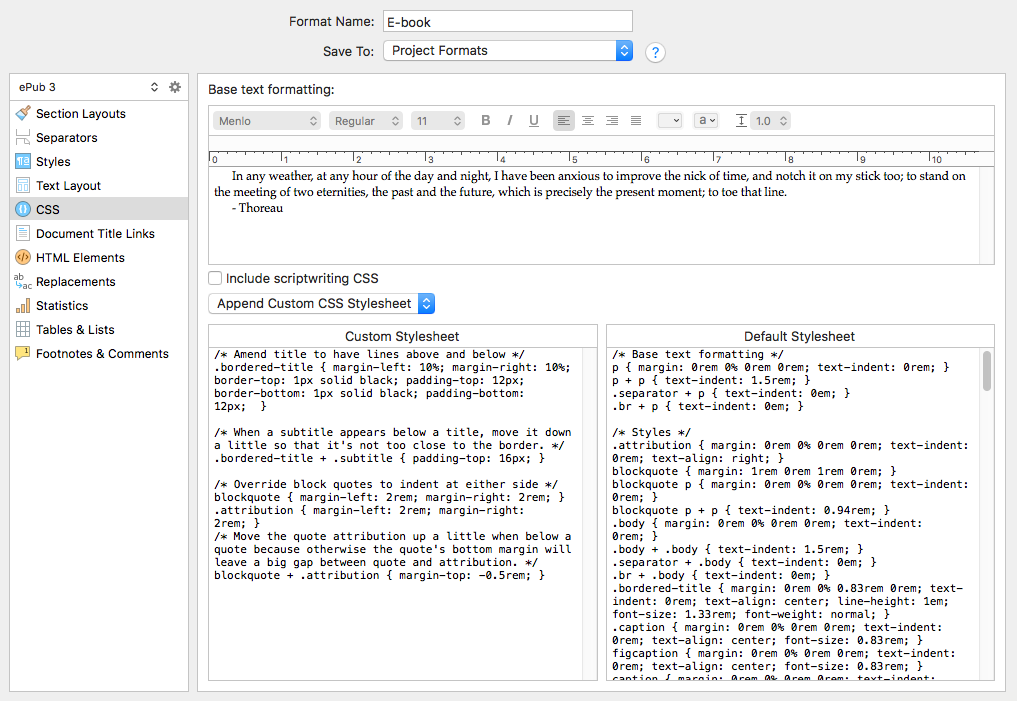
Compiling an Epub 3 file relies in large part on Scrivener 3’s new styles feature—for block quotes and other formatting to appear as expected in the exported ebook, you’ll need to apply styles to the text (something not available in earlier versions of Scrivener). To make the transition to Scrivener 3 as seamless as possible, for the time being it will offer the ability to choose between Epub 3 and Epub 2 export (and between older and newer versions of the Kindle export). This means that you won’t have to worry about updating the text in existing projects to use styles just to get it to work with Epub or Kindle export—you can continue to use the older exporters until you’re ready to update your text or start a new project.