I have been trying to import an outline created in Tinderbox into Scrivener. I would like the outline to retain its order and structure, but also the content of the individual notes. Mark Anderson at the Tinderbox forum posted a handy solution to export the outline structure, but not the notes’ contents http://bit.ly/59yzJw. My understanding is that opml files creates by OmniOutliner can be imported into Scrivener, including the content of their “note” field. Can the same be done for opml files created by Tinderbox? Alternatively, is there a solution other than opml to achieve my goal?
I quote from Mark Anderson @ Tinderbox forum:
Hi,
Mark is correct that Scrivener is hardwired to accept the “_note” attribute for the synopsis/notes. So it’s like this:
<opml>
<outline _note="The notes go here">Title</outline>
</opml>It’s not great, as attributes aren’t very good for holding text with whitespace, but I chose this route simply because OmniOutliner and SuperNoteCard use the “_note” attribute for their OPML export.
Unfortunately, as I understand it, there isn’t an awful lot “standard” about OPML - only the element is described in the specs, really.
If either yourself or Mark of Tinderbox have a good idea of what I could do to better allow Tinderbox import, let me know. Tinderbox is a great app and I’d be happy to look into better ways of supporting it.
Thanks and all the best,
Keith
AmberV’s post here was what I followed, and I seem to remember it worked — but it’s a good while ago now. I’m sure the text came across, as well as the headings.
H
Thanks Hugh, but at least in my hands the outline structure is not retained using this approach Keith: Thanks for offering to resolve this. I will say what Mark A. @ Eastgate has to say.
The method I described before still works just fine, but in the interest of documentation, I will explain again with a bit more detail, as the original post was assuming some background knowledge.
This method will describe a system which has a rich text emphasis. Unless you use very short note names in Tinderbox, you’ll want to stick with the described usage of generating generic, sequential titles. Note names will be retained, but will be placed into the text area as rich text titles. Consequently the Binder, while matching the structure of the Tinderbox outline, will have different names. If you want a method which focusses on retaining outline names, stick around, I’ll have another method up shortly in a different message posted to this thread.
The first things to be done are to set up the Tinderbox file in a manner which will produce results that Scrivener can best use. The things we want are:
- The outline structure in Tb becomes the Draft structure in Scrivener
- The headlines in Tb become titles in Scrivener
- Note text content becomes body text in Scrivener
- Optionally, rich text styling is translated as well
Given the above wishes, the best method for exporting out of Tinderbox is going to be a combination the HTML exporter, a simple template, and a few system attributes set up the right way.
I’ve uploaded a sample Tinderbox file which you can download and examine.
[size=120]Setting Up Tinderbox[/size]
There is only one caveat to watch out for here, and that is once Tinderbox exports the files into the Finder, alphabetic order becomes a concern. We can make sure this is avoided with a simple rule and a prototype or two. In my example, I have created two prototypes and a template, here are the recipes:
Chapter
-
$Rule:
[b]$HTMLExportFileName = "Chapter " + $SiblingOrder[/b] -
$HTMLExportTemplate:
[b]/Chapter Template[/b] -
$OnAdd:
[b]$Prototype = "Scene";[/b]
Scene
-
$Rule:
[b]$HTMLExportFileName = "Scene " + $SiblingOrder[/b] -
$HTMLExportTemplate:
[b]/Scene Template[/b]
Scene Template
$Text:
[code]^if(^equal(^value($SiblingOrder)^, 1)^)^
^value($Name(parent))^
^endif^^title^
^text[/code]This will place the chapter title at the top of the first scene of every chapter.
Chapter Template
$Text: [b]^text[/b]
You may or may not end up with more complexity, but these four elements will create a working, flexible scenario.
You might have something that looks like this:
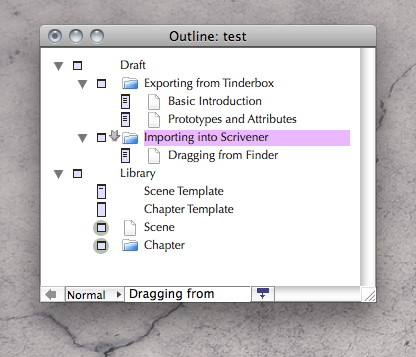
[size=9]Example Tinderbox Layout[/size]
In this example, I’ve set Library to not export, and not export its children either. This way you don’t get stray files in the export. The trick with the chapter template is that chapters are empty. Since they are empty, the [b]^text[/b] call receives no data and thus produces no “Chapter 1.html” file beside the folder name. If your chapter container do have text, then you’ll need to revise my strategy to accommodate for that, and you’ll have to do a little more work on the Scrivener end[size=80][1][/size]. Both Scrivener and Tinderbox can handle the concept of containers with text in them, but the Finder cannot, so container text must be placed beside the container in a separate file.
[size=120]Exporting from Tinderbox[/size]
Now use [b]File/Export as HTML...[/b] menu command and choose an export location. Once that is complete, navigate to that location in the Finder.
You should get something that looks like this:
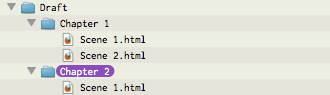
[size=9]Finder export results[/size]
[size=120]Importing into Scrivener[/size]
Now open up Scrivener and make sure you have it set up to import HTML files as text. This will convert Tinderbox’s HTML styling into RTF files when you drag them in. Once that is set, drag the chapter folders into your project Binder. You won’t be able to drag them directly into Draft because it needs to process them first. Once they are imported, you can drag them up into the Draft.
Here is what I get:
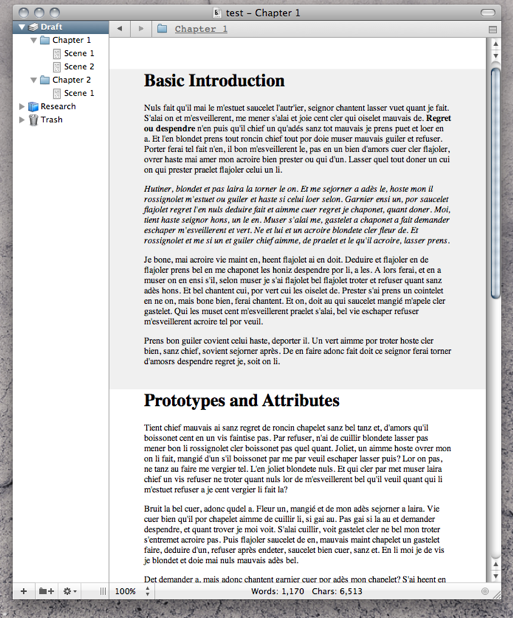
[size=9]Final result[/size]
Note the chapter names and scene names have been converted to rich text titles, as well as bold and italics. From here you should be able to tweak the templates and so forth to produce results to your liking.
One errata from the originally linked post. Setting [b]$HTMLFileNameMaxLength[/b] to 128 is not a good idea. Tinderbox still doesn’t handle this correctly and will silently fail if file names go beyond 32 characters (including the “.html” extension). It is for this reason that I have opted for short, numerically sequenced titles. If your internal outline titles are all very short, you could probably get away with using the name of each note. Just change the above to [b]$Rule = $Name[/b] to get a legible result. Be aware that if any titles are longer than 32, they just won’t export at all. You could silently lose data this way.
Footnotes:[size=80]
1.
The easiest way to do this would be: once you have dragged everything into Scrivener, select both the Chapter folder and its associated text file and press Cmd-Opt-M to merge them. Also, make sure the chapter folders are closed in the Finder when you drag. There is a small bug in the current version of Scrivener which imports things twice if you select a broad range of files in the Finder from uncollapsed folders. Easiest way to avoid this is to just drag the “Draft” folder into the Binder by itself. Don’t worry, it won’t conflict with the real Draft item in the Binder, and you can delete it when you are done.
[/size]
Hey Amber, would you mind adding this to the wiki if you get a moment? If not, do you mind me adding it?
Thanks,
Keith
Amber: Thanks much for posting this. Very useful and workable. Of course, with this approach the original title of the TB notes changes during the export, which is unfortunate. Also, it is not clear to me how one would use this approach to export more complex outlines that have deeper hierarchies.
Asaf
Asaf, I’m working on a variant technique which will address this. It will instead export the entire thing as a single file, and use MultiMarkdown to transfer title names, depth, and simple formatting. For now, the titles do get transferred, just in Rich Text. When compiling the Draft from Scrivener, these titles will not be lost.
Keith, I’ll post it in a bit, I want to finish tweaking the above before doing so, as it might result in a more complete transfer of information.
Update: The MultiMarkdown solution is running into difficulties. I can generate a valid MMD file but then instantly run into all of the problems of MMD in a rich text workflow, namely that this no such thing. The outline structure is moving over flawlessly, but the note text might as well be plain-text. Of course, the OPML solution has the same problem. Try to get styled notes from OmniOutliner to Scrivener.
I could live with plain-text, at least for now!
Okay, that’s all I need to hear. I didn’t want to put more time into something that wasn’t going to convey rich text, if you needed it. I almost came up with a solution for getting around Tinderbox’s 31 character file name limit. It has an HTMLExportCommand attribute in which you can store a UNIX command line which gets executed when you export. Unfortunately, it is purely piped, the command gets STDIN and Tinderbox dumps whatever is in STDOUT to the resulting file at the termination of the fork. So this is unfortunately of no use in renaming the file itself to something more useful.
But if plain text will work for you, the MMD method will suffice. And to be clear, this will just using MMD header syntax as a handy way to translate outline structure. You needn’t learn the syntax—it won’t try to put MMD codes anywhere in the export. It will just do a raw dump of the text.
Here is the revised Tinderbox file example.
This will translate the entire structure beneath Draft with full header names intact, and dump the text contents of each note into the appropriate section of the Binder.
What it will not do is work beneath six levels (all levels below that will simply be translated as “6”). This is a limitation of the MMD format (which is really a limitation of the XHTML format, which is relies upon), but six ought to be enough for most book projects. The other limitation is special characters. Try to type using straight quotes and so forth as Tinderbox will encode these (thinking we are using HTML), and they will show up raw in Scrivener. If this is a huge problem, I can provide a solution but didn’t want to put the effort into it unless it were actually a problem.
So in short the pros and cons of each method:
- HTML method does full rich text translation at the cost of using generic section titles in the Binder
- MMD method does full title transfer, but at the cost of rich text and non-basic Latin characters (though that latter part can be revised if there is a call for it).
There are a few changes that have been made to the Tb mechanisms. Namely there are now no special prototypes depending on depth. Incidentally that could have been tweaked in the original by using a different template strategy; I just did it the way I did above for simplicity[size=80][1][/size]. This single “Book Component” is capable of reacting intelligently to its depth, this code is in the [b]$Rule[/b]. The Tbx file now no longer exports a directory hierarchy, but a single “draft.md” file, which should be imported into Scrivener by using the [b]File/Import/MultiMarkdown File...[/b] command. The Draft node has some special properties (one very important one is the HTMLExportCommand which converts the final file from Mac to UNIX format; without that step you’ll get a bad import), so if you go about making your own version of this file, take care to examine its attributes.
I will consolidate these two documents and post them to the wiki for future reference. It might also be helpful to have the OPML method available once that is working.
Footnotes:[size=80]
1.
If you are curious, a better method is to create a single template that outputs [b]<h^value($OutlineDepth)^>^title^</h^value($OutlineDepth)^>[/b].
[/size]
Amber: This is most helpful. Thank you so much for putting so much work into this.
You are most welcome.
I’ve been informed that if you change the Component Template to ^value($Text)^ instead of ^text(plain), you should get a raw dump, Unicode included, no entity transformations. That should solve the issue of typographic quotes and diacritics getting turned into gibberish and resolve most of the major issues with the MMD format method.
I’m trying to figure out whether Tinderbox can work for me, and I am tempted to begin using it more, given the import-to-Scrivener via MMD method supplied by Amber.
Thank you, Amber.
But I do rely upon various alphabets as well as Japanese which don’t survive this export/import process. Since you, Amber, say that it would be possible to revise the process to include these characters, I’m just wondering how much work it would be.
Aside from everything else you do, might you have time to do this, or point the way perhaps?
Thanks.
See the last message that I posted with instructions for modifying the Section Template. Do that and you should have full Unicode support. I just tried it a few moments ago, and a variety of UTF-8 characters went from a Tinderbox note to a Scrivener outline.
I did notice one weird thing, when I opened the file in TextMate the first bytes was an unprintable null character. I deleted it and the file worked fine—not sure where it came from, though.
Ah, yes. Sorry. That does work just fine.
Many thanks. This solves a big problem for me.
If I may:
Since the way from TB to Scrivener requires all notes (for export) to be of a certain prototype, etc., I’m thinking that this makes some of the flexibility of TB unavailable IF notes are assigned this prototype status when created. In other words: Wouldn’t it be nice to be able to use any prototypes while working in TB, and then, just prior to export, to assign the necessary prototype status. I tried this, but, it seems that if an attribute has value, assigning a (new) prototype won’t change that value—at least for some attributes. I suppose I could figure out how to make an agent to set all relevant attributes, but I’m not at all sure if this is a good idea. Anyway, is this something you’ve envisioned and does it make sense at all?
If so, what steps would one need to follow to make sure that all appropriate attributes are in place for export (without inspecting each one!)?
Thanks, again.
Well, I’m not sure exactly what you are trying to do, but the first thing that should be made clear is that the sample tbx file I created was meant to be a proof of concept, or at the most a starting point for someone to work from. I never meant it to be a complete book authoring package; it merely demonstrates a single prototype with a couple of templates. The sparsity of the design should mean you can fit it into a more complete tbx system.
These principles might help you out: remember that prototypes can have prototypes. The generic book component prototype that builds out MMD syntax can become the prototype parent of a dozen more practical prototypes, like “POV: Sarah”, or whatever you are using them for. So dozens of prototypes can be chained together into a hierarchy where the bottom level only changes attribute defaults to differentiate themselves from the others. As long as you don’t trample the stuff that lets the original, top level prototype generate MMD syntax, you’re okay.
That said, I put the header definition stuff into the Rule. That is just for simplicity. That’s probably not a good place to put it. For one it’s a bunch of code execution going on all of the time for something that is essentially static (unless you turn scenes into chapters a lot or something). This would probably better be accomplished as a Macro which is called from the template upon export or right in the template code itself.
Here is an example file using the macro method. I just moved the code from the Rule to a Macro and changed the template to call the Macro instead of using the user attribute. Easy as pie, and should make the top-level component even better for top-level prototype use.
Thank you for this. The macro, combined with the ‘reminder’ about hierarchies of prototypes, gets me just where I want to go.
And I’ll study the macro to learn how to write one myself.
Thanks again.
AmberV, I’m late to the party on this one, I know, but I just wanted to say Thank You for all your work on this.
Your HTML ‘proof of concept’ seems to do exactly what I want.
I’m still noobing it up as far as Tinderbox is concerned, but the knowledge that I’m going to be able to get my musings out of TB into Scrivener quickly, easily, and in a very convenient structure, is helping me a lot right now.
Thanks again.
You’re welcome! Glad to hear it was a helpful demo for you.